SMOTE for Imbalanced Classification with Python
A hands-on tutorial for handling imbalanced datasets using SMOTE and imbalanced-learn in Python
Catalog
Click on this table of contents to jump to the corresponding section
When a dataset has more samples of one class and very few of another, the model tends to predict the majority class more often. This problem is called class imbalance. The Synthetic Minority Over-sampling Technique (SMOTE) helps fix this issue by creating new synthetic samples for the smaller (minority) class. This makes the dataset more balanced and helps the model learn both classes properly.
- SMOTE creates new synthetic data instead of copying existing samples.
- It improves accuracy for the minority class.
- Variants like ADASYN, Borderline SMOTE, SMOTE-ENN and SMOTE-TOMEK make SMOTE even more effective.
- It can be easily used with the Python library imbalanced-learn (imblearn).
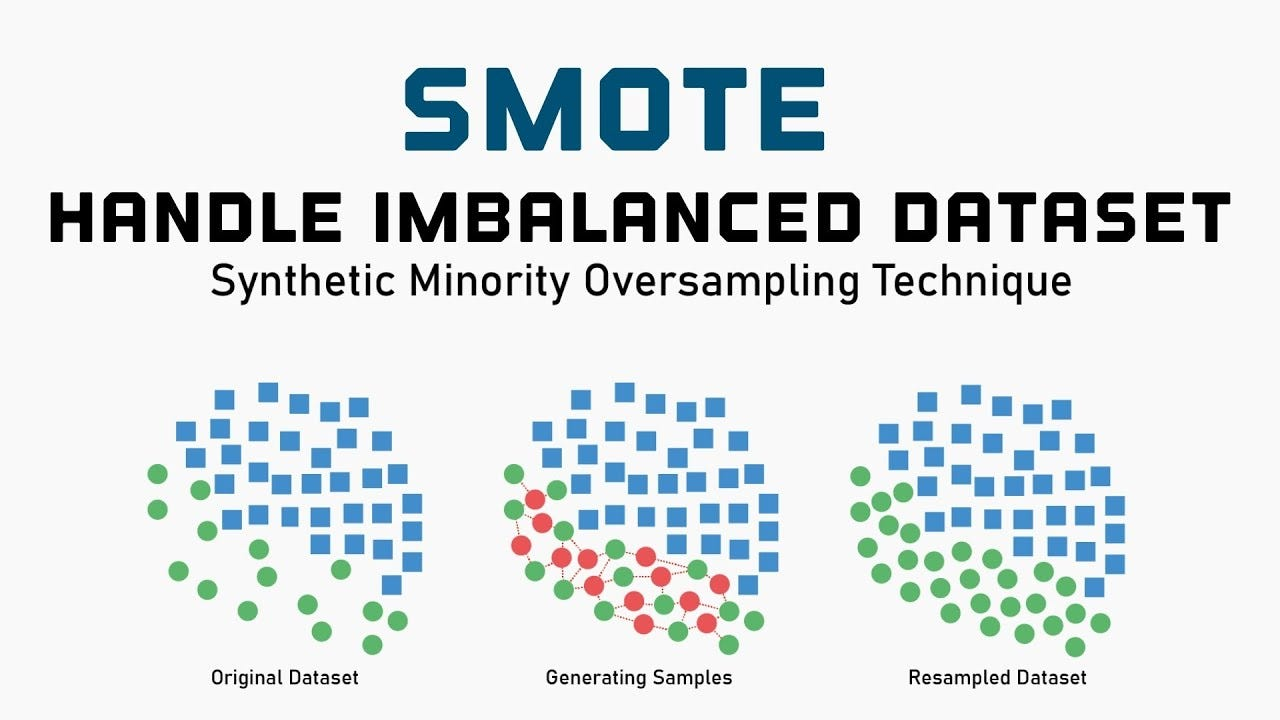
Synthetic Minority Over-Sampling Technique (SMOTE)
SMOTE is a data-level resampling technique that generates synthetics (artificial) samples for the minority class. Instead of simply duplicating existing examples, it creates new data points by interpolating between existing ones. This approach allows the model to learn broader patterns and reduces the risk of overfiting to repeated samples.
Working:
- Identify the Minority Class: The process begins by detecting which class (or classes) have significantly fewer samples compared to others
- Find Nearest Neighbors: For each sample in the minority class, SMOTE locates its k nearest neighbors (based on distance in the feature space). The value of k is a user-defined parameter that controls how many neighbors are considered.
- Generate Synthetic Samples: A random neighbor from these k nearest points is chosen and a new synthetic instance is created along the line segment connecting the original sample the the chosen neighbor. This ensures the new points are realistic yet distinct.
- Control Oversampling Amount: The number of synthetic samples to be generated is determined by an oversampling ratio, which is chosen so that both classes reach a similar size or desired balance.
- Repeat for All Minority Samples: Steps 2 to 4 are repeated for all minority class examples to produce enough synthetic data for balancing
- Form the Final Balanced Dataset: After generating these synthetic examples, the dataset becomes more balanced, helping machine learning models train more effectively and fairly across all classes
Step By Step Implementation
Here in this code we handles class imbalance in a credit card fraud dataset by applying SMOTE oversampling trains a logistic regression model and evaluates its performance using accuracy, classification report and confusion matrix.
Step 1: Import Required Libraries
- Import Pandas for handling CSV files and working with DataFrames.
- Import Matplotlib for basic data visualization and plotting graphs.
- Import SMOTE to handle class imbalance by oversampling the minority class.
- Import Seaborn for enhanced statistical data visualiation
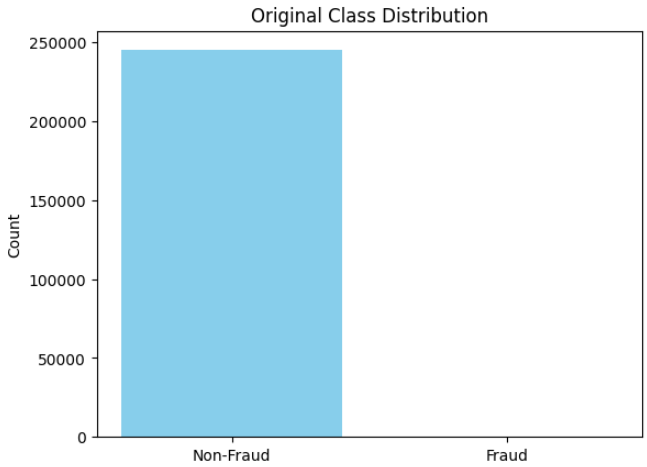
Step 2: Load and Explore the Dataset
- Load the credit card fraud dataset from CSV
- Separate features (X) and target variable (y)
- Handle missing values using median imputation
- Visualize the original class imbalance
Output:
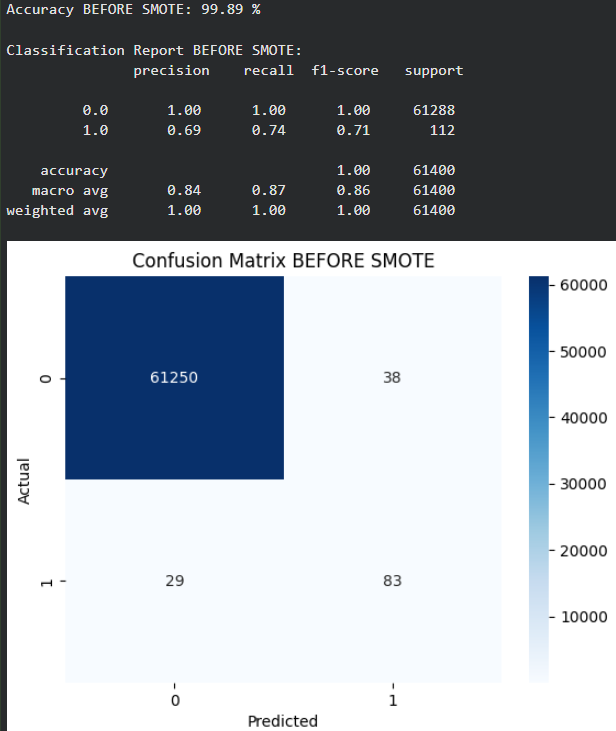
Step 3: Train Logistic Regression
- Split data into training and testing sets using stratification
- Train a Logistic Regression model on imbalanced data
- Predict test results and evaluate performance
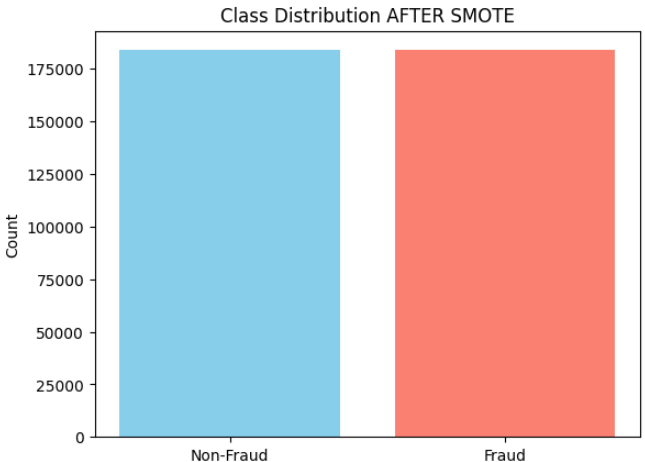
Step 4: Apply SMOTE to Balance Classes
- Apply SMOTE to oversample the minority (fraud) class
- Generate a balanced training dataset
- Visualize the new class distribution after SMOTE.
Output:
Step 5: Train Logistic Regression After SMOTE
- Retrain the model using the balanced dataset
- Predict results on the same test set
- Compare accuracy and classification performance
Output:
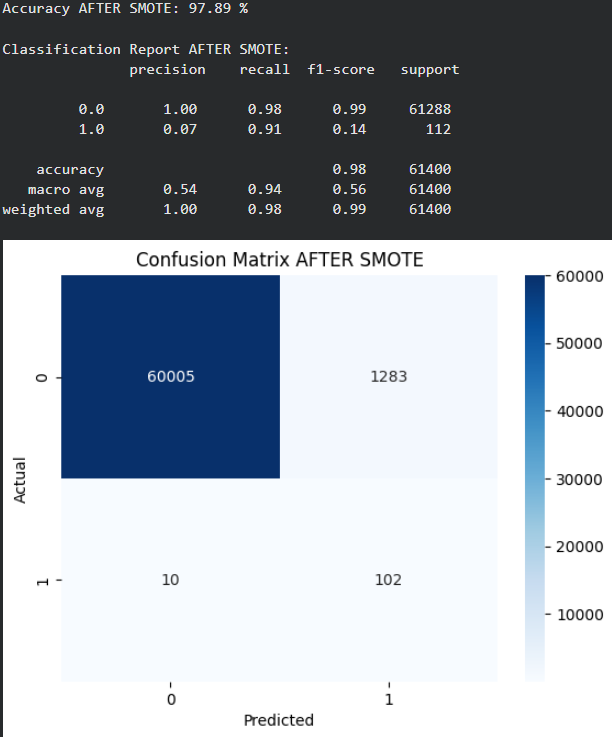
After applying SMOTE the model becomes better at detecting the minority class but at the cost of increased false positives highlighting the trade-off between recall and precision in imbalanced datasets.
- After SMOTE the model no longer favors the majority class so overall accuracy decreases but this reflects a more balanced learning process.
- Recall improves but precision collapses for minority class Class 1 recall rises sharply meaning most minority samples are detected but very low precision shows many false positives.
- Confusion matrix shows over-prediction of minority class A large number of majority samples are misclassified as class 1 indicating the model became too sensitive after SMOTE.
Variants of SMOTE
SMOTE effectively addresses data imbalance by generating synthetic samples, enriching the minority class and refining decision boundaries. Despite its benefits, SMOTE's computational demands can escalate with larger datasets and high-dimensional feature spaces. To enhance SMOTE's capability to handle various data scenarios, several extensions have been developed:
1. ADASYN (Adaptive Synthetic Sampling)
ADASYN stands for Adaptive Synthetic Sampling. It is an improved version of SMOTE that automatically focuses more on minority samples that are difficult to learn. Instead of generating synthetic samples uniformly, ADASYN creates more new samples for minority points that are near the decision boundary where the model usually makes more mistakes.
Working:
- Calculate the level of difficulty for each minority sample. Here samples surrounded by majority samples are considered harder to learn.
- Assign higher weights to difficult samples so that more synthetic examples are created around them.
- Generate synthetic samples by interpolating between each difficult sample and its nearest minority neighbors.
- The final dataset has more new samples near the boundary, improving the model’s ability to classify challenging regions.
Implementation:
Output:
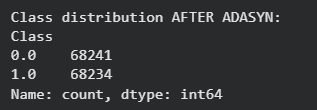
2. Borderline SMOTE
Borderline SMOTE is a modified version of SMOTE that focuses only on minority samples that lie near the boundary between classes. These are the samples most likely to be misclassified, so generating synthetic samples around them helps strengthen the classifier’s performance near decision boundaries.
Working:
- Identify minority samples that have many majority samples as their nearest neighbors and these are called borderline samples.
- Generate synthetic samples only around these borderline points, avoiding areas deep inside the majority class.
- This keeps the generated data clean and helps the model learn class boundaries more accurately.
Implementation:
Output:
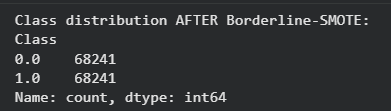
3. SMOTE-ENN (Edited Nearest Neighbors)
SMOTE-ENN combines two techniques i.e SMOTE for oversampling and Edited Nearest Neighbors (ENN) for cleaning. First, SMOTE generates synthetic data to balance the dataset. Then, ENN removes noisy or misclassified points from both classes to make the dataset cleaner and more reliable.
Working:
- Apply SMOTE to oversample the minority class.
- For each sample, look at its nearest neighbors.
- If most neighbors belong to a different class, remove that sample beacuse it’s likely a noise.
- The result is a balanced and denoised dataset that helps improve model performance and generalization.
Implementation:
Output:
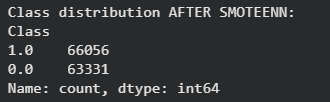
4. SMOTE-TOMEK (Hybrid Method)
SMOTE-TOMEK is a hybrid resampling technique that combines SMOTE and Tomek Links. After oversampling with SMOTE, Tomek Links are identified and removed to eliminate overlapping or borderline points between classes.
Working:
- SMOTE first oversamples the minority class by creating synthetic examples.
- Find Tomek Links as these are pairs of samples from opposite classes that are each other’s nearest neighbors.
- Remove those pairs, as they often lie in overlapping regions that confuse the model.
- The final dataset becomes balanced and cleaner, improving the separation between classes.
Implementation:
5. SMOTE-NC (Nominal Continuous)
SMOTE-NC (Synthetic Minority Over-sampling Technique for Nominal and Continuous features) is a version of SMOTE designed for datasets that contain both numerical and categorical variables. Traditional SMOTE works by interpolating between numeric features, but it fails when applied directly to categorical data because we can’t interpolate between category labels. SMOTE-NC fixes this by treating categorical and continuous features differently during the generation of synthetic samples.
Working:
- Identify which features in the dataset are categorical and which are continuous.
- For continuous features, generate synthetic samples using interpolation just like standard SMOTE.
- For categorical features, assign the most frequent category among the nearest neighbors instead of interpolating.
- Combine the newly generated synthetic samples to create a balanced dataset that respects both numeric and categorical data integrity.
When to Use Each SMOTE Variant
Let's discuss when to use each variant:
| SMOTE | Best use case | Main strength | When to use/ key notes |
|---|---|---|---|
| SMOTE (Standard) | Moderately imbalanced continuous datasets | Balances classes using synthetic interpolated samples. | Use for numeric, low-noise datasets works as a general solution |
| ADASYN (Adaptive SMOTE) | Datasets with region-wise imbalance | Generates adaptive synthetic data for hard-to-learn samples | Use for hard to classify minority regions to improve boundary learning |
| Borderline SMOTE | Minority samples close to class boundaries. | Generates samples near decision boundaries to reduce misclassification | Use when classes overlap or boundaries are frequently confused |
| SMOTE-ENN (Hybrid) | Noisy datasets with misclassified or ambiguous samples | Combines SMOTE and ENN to oversample and clean noisy instances | Use when the dataset has noise or outliers and we want a cleaner, balanced dataset. |
| SMOTE-TOMEK (Hybrid) | Datasets with overlapping classes needing clearer separation | Removes Tomek links post-SMOTE to reduce overlap and improve separation | Use when we want to improve boundary clarity after oversampling. |
| SMOTE-NC (Nominal Continuous) | Datasets with both categorical and continuous features. | Handles mixed features via numeric interpolation and categorical mode assignment | Use for datasets with categorical columns not suited for purely numeric data |
Lily and 4 people like this

Prev Post
Space The Final Frontier
Next Post
Telescopes 101

0 Comments
Leave a Reply
Recent Post
SMOTE for Imbalanced Classification with Python
12:28:00 16/05/2026
CLAHE Histogram Equalization with OpenCV: A Python Guide
12:06:00 16/05/2026
Histogram Equalization in Digital Image Processing
10:56:00 16/05/2026
Gaussian Noise Explained: What It Is and How It Works
10:36:00 16/05/2026
Python Image Blurring with OpenCV: Gaussian, Median & Bilateral Filter Guide
09:59:00 16/05/2026
Related Topics
Feeds
Don't miss what's next 👋
Enjoyed this content? Leave your email to get notified when we publish new insights, tutorials, and updates — no spam, ever.